Introduction
This document constructs a secure computing environment (SCE) motivated by the need to manage data securely in the public cloud. We take specific motivation from management of Private Health Information (PHI) under HIPAA regulations.
Front end working notes (need organize/integrate)
- The bastion can be reached using a bastion.pem file that has -r——– via chmod 400 for example.
- sftp to this bastion to move the private.pem key file to the bastion. Notice the -i bastion.pem argument precedes the user@dns:directory part of the sftp command
- On ssh to a private subnet EC2 instance see this page in the AWS documentation.
Links
- See the data security page relating to campus cyberinfrastructure.
- AWS HIPAA-aligned services
- AWS talk (YouTube) on HIPAA compliance
- AWS HIPAA compliance blog Part 1 Automation
- AWS HIPAA compliance blog Part 2 Deployment
- AWS HIPAA compliance blog Part 3 CloudFormation
- AWS HIPAA compliance blog Part 4 Config
- AWS HIPAA compliance architecture
- AWS HIPAA compliance white paper
Use Case Outline
The objective of this project is to accelerate medical research involving PHI via a HIPAA-aligned Business Associeates Agreement between a university and AWS. The strategy is to build a Secure Computing Environment (abbreviated SCE here) that addresses the three primary considerations: Data security (e.g. encryption considerations), reporting (e.g. logging access) and human use factors (e.g. access key best practices), all with the idea of reducing risk of compromise to the SCE. The end result is that the public cloud should disappear: Researchers simply focus on their research.
This content in relation to other resources
The content provided here may be thought of as a limited foray into an SCE. The links above are much more
comprehensive. A primary objective of the ‘limited foray’ is to provide a record of the thought process
de novo, i.e. it is an attempt to de-mystify matters for a medical researcher, our target audience.
Before proceeding into technical details of the implementation we therefore describe a typical use
case with related considerations. This is then referenced in more detail below.
Use Case
- Researcher awareness: Service catalog, word-of-mouth etc
- Project approved: IRB
- Request for Secure Computing Environment, billing mechanism (e.g. ITHS; Red Cap form)
- Research proceeds!
- Researcher wants data to go in…
- S3 would be the initial destination idea
- An RDS on a VPC private subnet would be the eventual destination…
- …via a S3 endpoint pull from S3
- Researcher wants a working environment on an EC2 on the private subnet
- with encrypted EBS
- kilroy consider using Workspaces which is HIPAA-compliant
- runs either through a Client or in the browser: A Virtual Desktop
- can look into S3
- configuration details TBD
- Researcher wants data to go in…
- Close out
Relevant Issues
- Logging/reporting: How the Researcher can report to a CRO ‘these data were used’ at the table row level
- Does this work differentiate a bespoke versus a multi-team / shared data project?
- Access constrained to certain IP addresses only (CIDR block)
- NetID authentication
- Technical support from within UW
- If data are breeched: What is the response plan, how does the vendor participate?
- Is a ‘third party solution’ path worth exploring?
Secure Computing Environment Framework
The framework for an SCE is a set of guiding ideas and concepts, particularly with the idea of establishing a common vocabulary. We develop this framework here in the introduction and follow this with three following sections:
- Technical details for building a secure computing environment (SCE) on AWS
- A first example system with synthetic data
- A second example system using OMOP data
Both example SCEs incorporate synthetic data; the second being built upon the Observational Medical Outcomes Partnership (OMOP) unrestricted SynPUF dataset.
In a simple view HIPAA regulations require that data be encrypted both at rest (on a storage device) and in transit (moving from one location to another). In addition all transactions around PHI data should be logged in a traceable manner to validate the assertion that only authorized individuals have had access to PHI.
HIPAA regulations may be seen through the lens of NIST; we find for example the NIST HIPAA Security Rule which is detailed in NIST Special Publication 800-66 Revision 1. This document discusses HIPAA=compliant implementations in practice.
Putting a conforming technical system in place is fairly straightforward though detailed (Part 1). Satisying conditions for HIPAA compliance in a real implementation also involves sociological elements. Real implementations operate under a Shared Responsibility model: AWS provides necessary security measures while practitioners build and operate the environment according to established practices; including documentation and logging access. HIPAA compliance is more than using HIPAA-aligned technologies from AWS.
We proceed with the following program:
- Complete the preamble with an expanded version of the User Story and open question list
- Part 1: Instructions for building a secure compute environment (SCE) on the AWS cloud
- Constructing a Virtual Private Cloud
- Constructing storage, compute and data management elements
- Logging and tracking activity
- Describe Proof-of-Concept A
- Simple; including a small synthetic dataset
- Obtaining and operating up this data
- Examining logs
- Cost estimate
- Describe Proof-of-Concept B
- Substantial synthetic dataset
- Queryable Redshift database
- Web application supporting data visualization
- Cost estimate
While this study uses AWS our team is also building comparable structures on other cloud platforms, notably on the Microsoft Azure public cloud.
Links
- The NIST 800-66 HIPAA Compliance documents
- Note that this cross-links to NIST 800-53 in Appendix D: A supporting document
- HIPAA home page
- HIPAA on Wikipedia
- HIPAA Privacy Rule Summary
- AWS Accelerator: NIST broad spectrum
- Observational Medical Outcomes Partnership (OMOP)
- Email contact at DLT to advise of HIPAA use
Admonitions
- When using a DLT-provided AWS account for PHI you must notify DLT of this in advance: cloud@dlt.com
- The acronym SCE is used extensively on this page to denote a Secure Computing Environment.
- AWS has more than twelve HIPAA-aligned technologies. Only these technologies may come into contact with PHI. Other technologies can be used provided there is no such contact.
- HIPAA compliance is an obligation of the data system builder, the medical researcher and the parent organization(s).
- The public cloud is very secure: physically and technologically. Compromise is most likely to be caused by human error.
- File names may not include PHI.
- AWS has many virtual machine / instance / EC2 types, particularly general purpose computers called m-type. These are fine to use in an SCE. There is also a lightweight instance type called a t-type. The t instance type by its nature will not connect to a Dedicated Tenancy VPC. Hence t-type AWS EC2 instances may not be used in an SCE.
Extended User Story
- A scientist K receives approval from the IRB to work with PHI data.
- Intent: Analyze these data in a Secure Compute Environment (SCE)
- K initiates a cloud solution project that includes a billing mechanism
- K contacts IT professional J to build an SCE as a working environment
- Initial steps align K and J to build the SCE
- The SCE is set up by J with K’s help as described below
- Data are uploaded to storage on AWS from a secure device
- K is provided with access to the SCE
- Specifically
- A pem file and ip address of a bastion server B
- A login and password to a private subnet EC2 instance
- Notice there is no IAM User account involved
- Console access not needed
- K logs on to the SCE
- There is some potential initial configuration, e.g. installing software
- K carries out data analysis over time; system activity is automatically logged
- There are a number of stretch goals to call out
- Patient-held devices could contribute data streams e.g. via phone app using the API Gateway
- These data supplement the research
- The study concludes, data and results are preserved, log files preserved, the SCE is deleted
- No trace remains
- Specifically
Supplemental SCE ideas
- Simplest use case is the static scenario given above
- Expansion use cases will involve external devices (phones, sensors)
- Data direct to cloud: Authenticate, validate data, match to patient
- Standard format (HL7? CCD?)
- Further expansion
- Bidirectional data sharing
- Device, cloud, EHR
- End result: Allowed persons (care / research) can get to all of this data
- Bidirectional data sharing
- On the cloud: How do we manage installing / updating tools for analysis?
- Include Machine Learning; Visualization, Comparatives w/r/t analytic datasets (reference genome for example)
- This cloud story will progress in stages
- From an IT view: What are the SCE constraints?
- Are AWS Services available within a VPC? IS a VPC required?
- Currently there are 13 HIPAA-aligned technologies
- API Gateway
- Would be the mechanism for allowing a phone to report blood pressure
- Direct Connect
- Snowball
- DynamoDB
- EBS
- EC2
- EMR
- ELB
- Glacier
- RDS
- Aurora
- Redshift
- S3
- API Gateway
- This number is growing; and new contributions accrue automatically to the BAA
Intermezzo Kilroy stack (a list of must-fix details)
-
Questions from Dogfooding on March 23 2017
- A VPC costs nothing per day. EC2, EBS, networking egress (9 cents per Gig EC2 to internet), S3 egress is 9 cents per Gig up to 10 TB (then it drops a bit for more)
- Other charges: NAT Gateway is 4.5 cents per hour plus 4.5 cents per Gigabyte
- S3 also costs… now 2.3 cents per GB-month. RDS costs based on chosen instance size.
- Medium instance runs $1.16 per hour for the EC2 instance (which I see in the RDS console; but not in the EC2 console)
- $0.10 per GB-month for the storage which is equivalent to the EBS rate
- The I/O rate against the storage is 20 cents per one million requests so essentially free
- Backup storage is automated; and that costs at the S3 rate, 2.3 cents per Gig (less than the EBS snapshot cost)
- While we’re here: What is the EBS snapshot cost? To S3: 5 cents per GB month
- Let’s talk Stop
- Launch: I am pulling an AMI out of S3 onto an EBS root volume (the OS is part of this) attached to an EC2
- This is EBS-backed AMI. There is also Instance Store-backed AMIs which would be for insanely fast local solid state drive access: Because these install directly into the solid state drive on the EC2, not on an EBS.
- I have an EC2 and I click Stop: Now I am paying for its EBS. That is: The EBS persists. To pay snapshot rate (0.05 per GB mo) I have to snapshot this EBS.
- The snapshot runs $0.05 / GB month an d this is on the portion of the EBS it needs to save; not “all of it”
- It might make sense to store a /data volume in S3 to save money. But this is splitting hares.
- Now I want to go back to my EC2 (which I stopped) from my Snapshot.
- Now I want to create an AMI: Ok do that. It is a snapshot plus a little bit of metadata about the instance
- Now I can re-start the AMI
- This is the more typical use case
- In fact from a stop work and start again later think AMI
- Philosophically get in the habit of adding a data partition to decouple your data from your compute
- Code base: GitHub
- So now the Launch process can include User Data which is a script that loads the code base from GitHub
- To avoid doing manual security patches: User Data lives outside the AMI and can install packages like Python 2.7 and GitHub pulls and so on; but there is a backward compatibility possible issue
- Launch: I am pulling an AMI out of S3 onto an EBS root volume (the OS is part of this) attached to an EC2
- Changing instance type
- Stop
- EC2 console
- Change instance type
- Upgrade! T2.micro to P2.16X
- Change instance type
- AMI
- Tame deal
- Create VPC…
- Does my VPC need a CIDR that doesn’t overlap other ones in my account? 10.0.0.0 is very popular…
- VPCs can have overlapping CIDR blocks. However not if they are going to be peered.
- VPN also can create conflicts. So yes: Overlap is fine when they are independent bubbles.
- So: Peered VPCs are to be avoided and must not have collisions; otherwise fine
- Stipulate ‘Default Tenancy’:
- Shared versus dedicated: Shared is now allowed; so do not use Dedicated Tenancy for HIPAA: This is now in the BAA as unnecessary for HIPAA compliance.
- Creating subnets: AZ: VPC is regional
- Subnets are associated with AZs and should be intentionally designated
- Using multiple AZs (multiple subnets across AZs) will make the VPC “present” in those AZs
- There is a charge for inter-AZ bandwidth: 1 cent per Gig which is one ninth the egress to internet rate
- for SCE it is more controlled to be in just one AZ
- Going multi-AZ would be a high availability strategy which is a compute-heavy idea
- Does my VPC need a CIDR that doesn’t overlap other ones in my account? 10.0.0.0 is very popular…
- A VPC costs nothing per day. EC2, EBS, networking egress (9 cents per Gig EC2 to internet), S3 egress is 9 cents per Gig up to 10 TB (then it drops a bit for more)
- AB: How to do determine Account has been registered at AWS as PHI/HIPAA-active?
- Email aws-hipaa@amazon.com and include the account number
- Is there a DLT component?
- Generate and incorporate a scientist workflow diagram with extensive caption per User Story
- Generate and incorporate a complete SCE architecture diagram near the top of this
- Create a sub-topic around L: In coffee shop, in a data center (out of Med Research), etcetera
- Risk
- coffee shop
- Verify correct: There is one private address space per VPC: All VPC resources map to this
- …and Public elements also have world-facing ip addresses
- …and all private addresses are stable; no bounce problem
- 10.0.0.x as the address space of Spublic is its private VPC address space
- That is: 10.0.0.x is actually a private ip address for a public-facing instance
- We get both public ip address x.y.z.w and a DNS entry ec2-etcetera
- Inside the VPC a public ip always resolves to a private ‘10.0.0.9’ to keep traffic inside the VPC
- ec2-etcetera DNS entries change when the machine bounces; as do ip addresses
- How does one verify that auto-generated resources are not public?
- Equivalent: How are auto-generated resources assigned to subnets?
- How are private subnet addresses determined? “Pick one”?
- This is tremendously important so that a new Wi is not publicly visible
- Look at the VPC Routing Table “default subnet” column (verify this is correct)
- Key management story
- K_Bastion must reside on L. How is this considered secure? Chain of custody from origination?
- K_EC2private same; and must be carried via scp to B
- B is a single point of failure compromising EC2private
- Password-protection on B
- Group access: one login is not an option. Now we have Users.
- For that matter should ec2-user be logging on to EC2private to do work?
- How do keys work in view of an AMI source?
- Is the public B ip (Elastic or not) address vulnerable? Risk++ How to use SG and/or CIDR?
- EBS Encryption Keys: Risk++
- EBS encryption select has an account default key: Details are listed below
- Risk: Check DLT T&C; “who is responsible for the risk?”
- Risk: Boot volume is not encrypted
- Risk: EC2 swap space and PHI
- Scale problem: Manage Wi keys and roles
- If K and her team are not IAM Users how do they cut cost by stopping machines?
- CLI from L works but requires authentication
- For the learner we must differentiate SQS and SNS
- S3 event notification link
- [AWS notification how-to[(http://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html)
- Describe the PubSub concept
- Try this: SQS is a queue where things sit; polling it triggers processes
- CANVAS LMS is apparently a good example since students are interacting with it frequently
- What is Ansible and what does it get us?
- Configuration management
- cf Chef and Puppet
- In what sense does the NAT Gateway prevent or not prevent us from poisoning ourselves?
- The RT / subnet section needs review
- What are the tradeoffs in building B, M and Wi from AMIs?
- Config management tool: Option 1 (Ansible Chef Puppet)
- How does ‘sudo yum update -y’ happen?
- Manually take a stale AMI and update it and re-save it (and update the hot machine)
- “You still have to manage the OS” is part of Shared Responsibility
- Cost: Shut down instances over the weekend when not IAM Users…
- Logging: CloudWatch and CloudTrail are AWS logging services; frequently parsed using Splunk
- Intrusion detection!
- Jon Skelton (Berkeley AWS Working Group) reviewed use of Siricata (mentions ‘Snort’ also)
- Intrusion detection!
- Filenames may not include PHI.
- ‘IT, Admin and Research approvals.’
- Figure out ‘Default subnet’ for new resources: Not accidentally public when auto-generated
- Explain how small CIDR block ranges do not conflict with the internet
- Bastion server inbound ip range should be modified to match UW / UW Med / etcetera
- Unless you want people able to wfh
- Also differentiate the UW VPN CIDR block
- Bastion and Sprivate W: More details on the configuration steps!
- Enable cloudwatch checkbox? Yes
- Missing instructions on setting up S3 buckets: For FlowLog and for DataIn
- Be clear that subnet CIDR blocks are always for the private subnet component.
= Subnet public means a second set of (public: on the internet) ip addresses
- These map to the private subnet addresses.
- Glossary
- Ansible
- Regions and Availability Zones on AWS
- Bastion Server
- Siricata / Snort
- Direct tools like ssh and third party apps like Cloudberry
- Dedicated Instance
- Lambda Service: A micro-service which is code that runs under certain trigger conditions; see the dedicated cloudmaven page.
- NAT Gateway: A Diode that permits a private sub-net instance to access the internet without the internet having access back.
- Notice that an EC2 can use a NAT Gateway to transparently install software; but if this is malware then you have done it to yourself.
- HIPAA-aligned components of AWS
- “How can you be using Lambda? It is not on the list…?”
- Tools that do not come in contact with PHI can be thought of as ‘triggers and orchestration’.
- Services that may come in contact with PHI can be described as ‘data and compute’
- This block of text was formerly the close-out plan for the POC; please review
- Set up Ansible-assisted process for configuring and running jobs on EC2 instances
- Pushing data to S3
- Console does not seem like a good mechanism
- Third party apps such as Cloudberry are possible…
- AWS CLI with scripts: Probably the most direct method
- How does the SCE fire up arbitrary EC2 instances as needed?
- Launch W x 5 Dedicated instances, call these Wi
- Assign S3 access role
- Encrypted EBS volumes
- S/w pre-installed (e.g. genomics pipelines)
- Update issue: Pipeline changes, etcetera;
- Wi can be pre-populated with reference data: Sheena Todhunter operational scenario
- Assumes that a SCE exists in perpetuity to perform some perfunctory pipeline processing
- On B
- Create SQS queue of objects in S3
- Start a Wi for each message in queue…
- Go
- Latest pipeline… EBS Genomes… chew
- If last instance running: Consolidate / clean-up
- SNS topic notifies me when last instance shuts down.
- Run Ansible script to configure Wi (patch, get data file names from DynamoDB table, etcetera)
- Get Ws the Key from E
- The Ws send an Alert through the NAT gateway to Simple Notification Service (SNS)
- Which uses something called SES to send an email to the effect that the system is working with PHI data
- Ws pull data from S3 using VPC Endpoint; thanks to the Route table
- Ws decrypt data using HomerKey
- Ws process their data into result files: Encrypted EBS volume.
- Optionally the result files are encrypted in place in the EBS volume.
- Through S3EP_O the results are moved to S3.
- Wi sends an Alert through the NAT gateway to SNS
- which uses something called SES to send another email: Done
- Wi evaporates completely leaving no trace
Plan for the SCE POCs A and B
- Build a system architecture and diagram
- Anticipate
pipeline, pipeline - EMR / data warehouse / Red Cap survey system / new clinical data / sensors
- Destinations are RDS, S3, EBS
- AWS big box, VPC inside, Public and Private subnets inside VPC
- NAT gateway inside the Public subnet box
- Internet Gateway on boundary of VPC
- S3 Endpoint on boundary of VPC
- Anticipate
- Artificial data 1
- static historical synthetic data (from EMR)
- IOT stream
- anticipate study-to-clinical pipeline
- Complete system including analytical tools
- include R, Python, Jupyter
- Artificial data 2 see KS
Part 1. Building an SCE
We use boldface abbreviations for system components. We also present tagging and naming resources using a short identifier string unique to each project: The Project Identifier Tag (abbreviated PIT).
Our main objective is to use a Laptop L or other cloud-external data source to feed data into an SCE wherein we operate on that data. The data are assumed to be Private Health Information (PHI) / Personally Identifiable Information (PII).
- Write down or obtain a Project Identifier Tag (PIT) to use in naming/tagging everything
- This is a handy string of characters
- In our example here PIT = ‘hipaa’. Short, easy to read = better
- Identify our source computer as L, a Laptop sitting in a coffee shop
- This is intentionally a non-secure source
- L does not have a PIT
- L could also be a secure resource operated by Med Research / IRB / data warehouse
We are starting with a data source and will return to encryption later. The first burst of activity will be the creation of a Virtual Private Cloud (VPC) on AWS per the diagram above. We assume you have done Step 0 above and are acting in the capacity of a system builder; but you may not be an experienced IT professional. That is: We assume that you are building this environment and that you may or may not be doing research once it is built; but someone will.
VPC via Wizard versus manual build
The easiest way to create a VPC is using the console Wizard. That method is covered in a section below and it can automate many of the steps we describe manually. We describe the manual method to illuminate the components.
1A: Start
Initial Required Action
As SCE builder your absolute First Priority Step 0 Must Do is to designate to AWS and DLT that the account you are using involves PII/PHI/HIPAA data. Contact DLT (the AWS account provider) with your account number using email address cloud@dlt.com. Your message should be to the effect that this account will work with PHI.
Cost tracking and cost reduction
- This will be a multi-day effort. Shut down instances to save money at the end of the day.
CIDR block specification
The CIDR block syntax uses a specification like 10.0.0.0/16. This has two components: A ‘low end of range’ ip address w.x.y.z and a width parameter /N. w, x, y and z are integers from 0 to 255, in total providing 32 bits of address space.
N determines an addressable space of size s = 2^(32 - N). For example N = 24 produces s = 2^8 or s = 256 available addresses, starting at w.x.y.z. Hence z (and possibly y) would increase to span the available address space.
Another example: Suppose we specify 10.0.0.0/16. Then s = 2^16 so 65536 addresses are available: 10.0.0.0, 10.0.0.1, 10.0.0.2, …, 10.0.1.0, 10.0.1.0, …, 10.0.255.255. y and z together span the address space.
These ip addresses are defined in the VPC, contextually local within the VPC.
Any subnets we place within the VPC will be limited by this address space.
In fact we proceed by defining subnets within the VPC with respective
CIDR ranges, subranges of the VPC CIDR block. In our case the first subnet will
have CIDR = 10.0.0.0/24 with 256 addresses available: 10.0.0.0, 10.0.0.1, …,
10.0.0.255. Five of these are appropriated by AWS machinery.
The second subnet will be non-overlapping with CIDR range = 10.0.1.0/24.
Since AWS appropriates five ip addresses for internal use (.0, .1, .2, .3, and .255) we should look for ways of making ip address assignment automatic.
1B. Create a Virtual Private Cloud
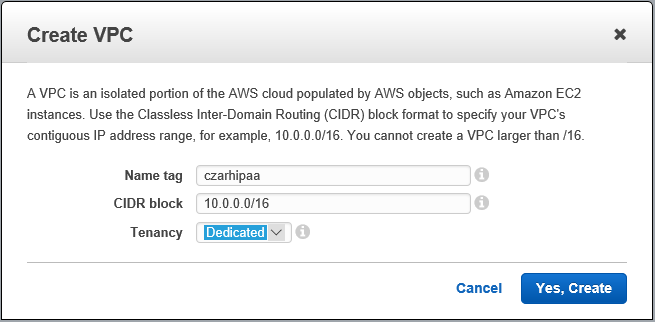
Build the VPC
Here we abbreviate elements with boldface type. In most cases the entity we create can be named so to remind you: For consistency we have come up with a Project Identifier Tag like ‘hipaa’ so that each entity can be given a PIT name: ‘hipaa_vpc’ and so on. In naming associated S3 buckets: The name may be harder to produce because it must be an allowed DNS name that does not conflict with any existing S3 buckets across the entire AWS cloud.
- From the console create a new VPC V
 1
1
 2
2
 3
3
-
Give V a PIT name
-
V will not use IPv6v.
- V will have a CIDR block defining an ip address space
- We use 10.0.0.0/16: 65536 (minus a few) available addresses
- V automatically has a routing table RT
- Select Routing Tables, sort by VPC and give RT a PIT name
- ‘hipaa_routingtable’
- The routing table is a logical mapping of ip addresses to destinations
- Select Routing Tables, sort by VPC and give RT a PIT name
- V is automatically given a security group SG
- Select Security Groups, sort by VPC and give SG a PIT name
- ‘hipaa_securitygroup’
- Select Security Groups, sort by VPC and give SG a PIT name
- Create an associated Flow Log FL
- In March 2017 the AWS console UI was a little tetchy so be prepared to go around twice
- On the console view of the VPC: Click the Create Flow Log button
- Assuming permissions are not set: Click on the Hypertext to Set up permissions
- Because: We need to define the proper Role
- On the Role creation page: Give the Role a PIT name; Create new; Allow
- You now have an IAM Role for FlowLogs
- This gives the account the necessary AWS permissions to work with Flow Logs
- In so doing we fell out of the Create Flow Log dialog so… back around
- Return to the VPC in the console
- Click on Create Flow Log
- Filter = All is required (not “accepted” and not “rejected” traffic)
- Role: Select the role we just created above
- Destination log group: Give it a PIT name
- Example: hipaa_loggroup
- Assuming permissions are not set: Click on the Hypertext to Set up permissions
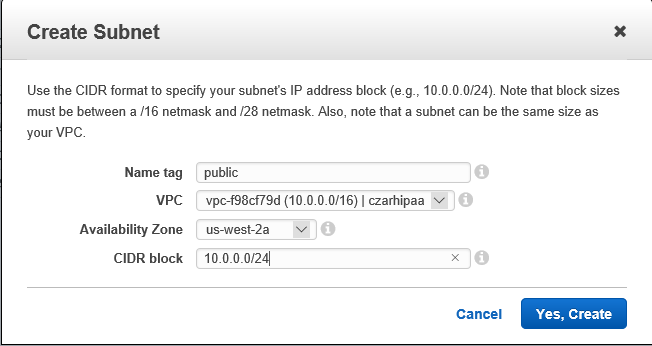
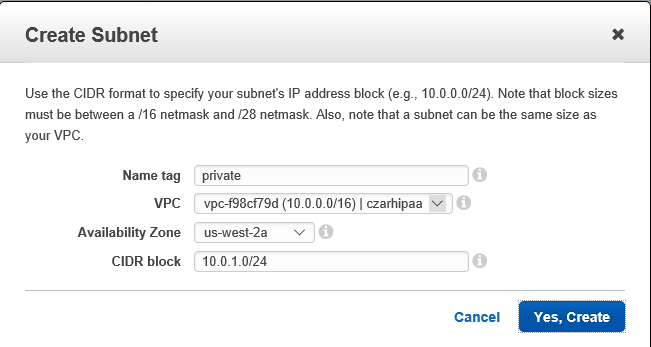
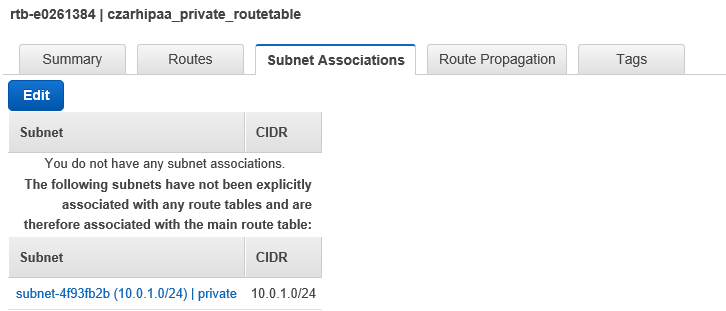
- Create subnets Spublic and Sprivate
 4
4
 5
5
 6
6
 7
7
 8
8
- The private subnet **Sprivate** is where work on PHI proceeds
- CIDR block 10.0.1.0/24
- **Sprivate** will be firewalled behind a NAT gateway
- This prevents traffic in (such as ssh)
- The public subnet **Spublic** is for internet access
- CIDR block 10.0.0.0/24
- **Spublic** connects with the internet via an Internet Gateway
- **Spublic** will be home to a Bastion server **B**
- **Spublic** will be home to the NAT Gateway **NG** mentioned above
- **B** and **NG** are on the public subnet but also have private subnet ip addresses
- That is: Everthing on the public subnet also has a private ip address in the VPC.
- This will use the private ip address space
- Public names will resolve to private addresses within the VPC at need.
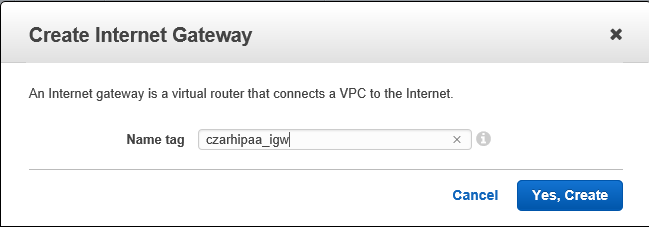
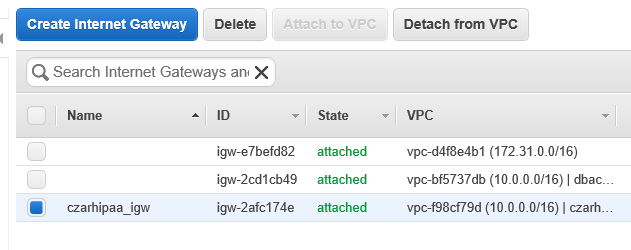
- Create an an Internet Gateway IG
 9
9
 10
10
 11
11
 12
12
- Give a PIT name as in 'hipaa_internetgateway'
- Attach hipaa_internetgateway to **V**
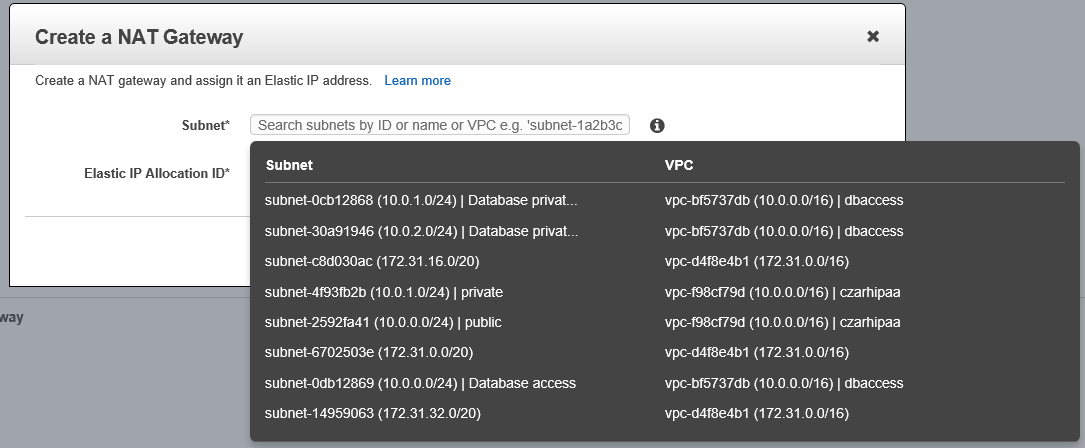
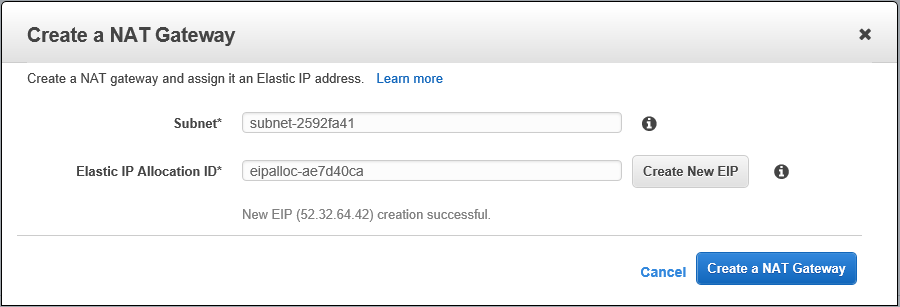
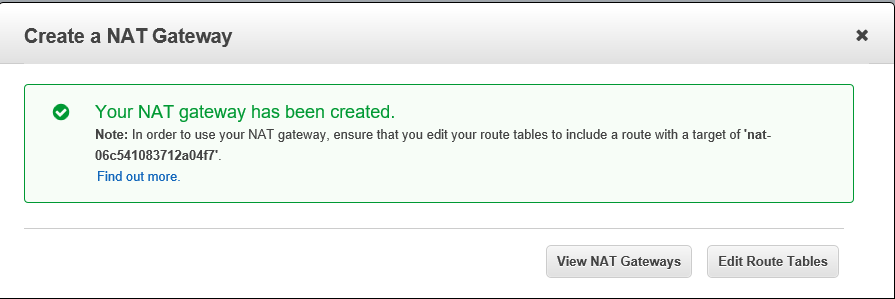
- Create a NAT Gateway NG
 13
13
 14
14
 15
15
 16
16
- Give it a PIT name
- Elastic IP assignment may come into play here
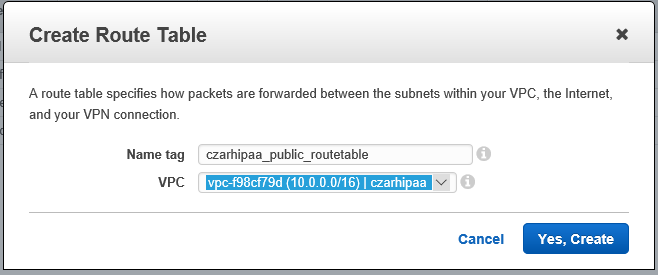
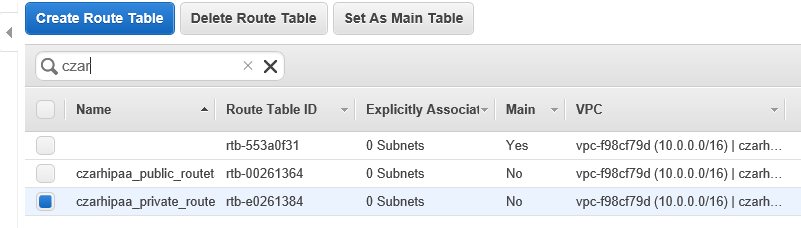
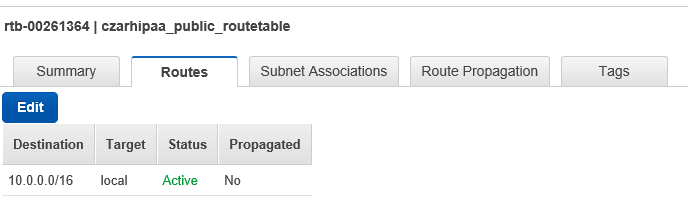
- Create a route table RTpublic
 17
17
 18
18
 19
19
 20
20
 21
21
 22
22
 23
23
- Give it a PIT name: 'hipaa_publicroutes'
- This will supersede the **V** routing table **RT**
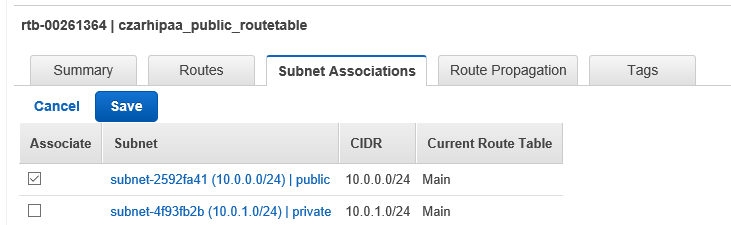
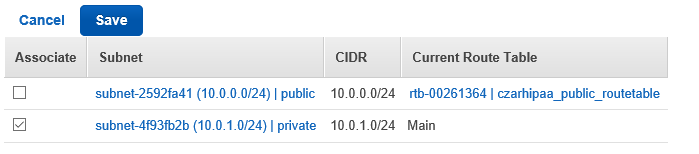
- Select the Subnet Associations tab
- Edit subnet association to be **Spublic**
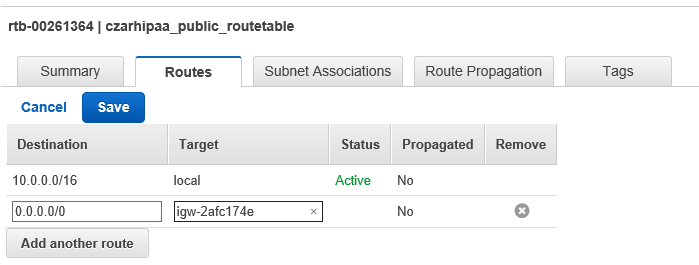
- Select the Routes tab
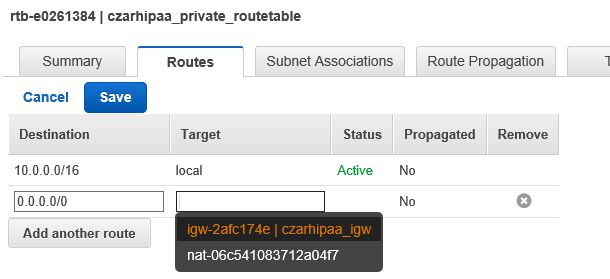
- Edit (under Routes) and add 0.0.0.0/0 pointing to **IG**
- public route table RTpublic
 24
24
 25
25
 26
26
 27
27
 28
28
Note: The console column for subnets shows “Auto-assign Public IP” and this should be set to Yes for Spublic. Note the column title includes the term Public IP. The Private subnet should have this set to No. If necessary change these entries using the Subnet Actions button.
Note: In the subnet table find a “Default Subnet” column. In this work-through both Spublic and Sprivate have this set to No: There is no default subnet. This will be modified later via the route table RT in V.
RT reads:
10.0.0.0/16 VPC "local"
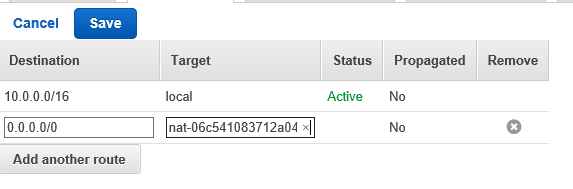
0.0.0.0/0 NAT gateway
RTpublic (hipaa_publicroutes) has
10.0.0.0/16
0.0.0.0/0 Internet Gateway
We now have two RTs. hipaa_routingtable (default for the VPC in general) and for Spublic (hipaa_publicroutes). Notice that RT operates by default and RTpublic supersedes this on Spublic. This means that new resources on Sprivate will by default use NG which is what we want.
The V RT 0-entry points at NG: All internet-traffic will route through NG. NG does not accept inbound traffic. This is by default. (Analogy: Home router)
Spublic has the custom RTpublic which routes non-local traffic to the IG, i.e. the internet. This does accept inbound traffic allowing us to ssh in. This is an exception to the default.
1C S3 buckets and EC2
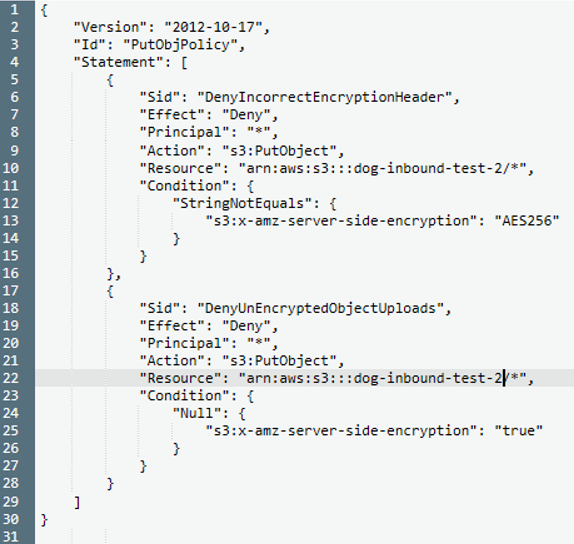
S3 Encryption policy
We create new S3 buckets associated with projects and assign them a Policy to ensure that Server-side encryption is requested by anyone attempting to upload data. This ensures the data will be encrypted when it comes to rest in the bucket.
AWS link for S3 server-side encryption policy for copy-paste
 )
)
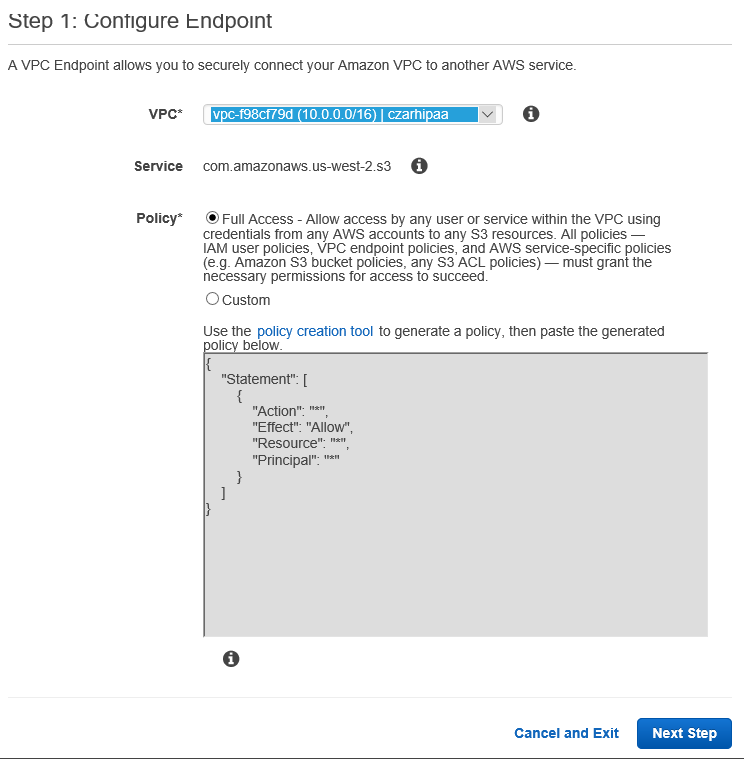
S3 Endpoints
 29
29
 30
30
An S3 Endpoint is routing information associated with the VPC. S3 access from the VPC should not go through the public internet; and this routing information ensures that. The S3 Endpoint is not subsequently invoked; it is simply infrastructure. For example an EC2 instance might access an S3 bucket via the AWS CLI as in
% aws s3 cp s3://any-bucket-name/content local_filename
1D. Building a Bastion Server B
- On V create a public-facing Bastion Server B
- B has only port 22 open (to support ssh)
- B uses Secure Groups on AWS to limit access to only a subset of URLs
- B can be a modest general-purpose machine such as a m4.large
- In this example we choose an m4.large running AWS Linux
- DO NOT USE T instances
- They will not connect to our Dedicated Tenancy VPC: This is not supported.
- Go through all config steps: Memory, tags;
- Security group is important
- Create a new security group
- PIT name: hipaa_bastion_ssh_securitygroup
- Description = allow ssh from anywhere
- Notice that in the config table “Source” is 0.0.0.0/0 which is “anywhere”
- Best practice is to restrict the inbound range
- Consider differentiating UW from the UW-VPN
- This would allow someone to log in from anywhere VIA the UW VPN
- Key pair use a PIT as ‘hipaa_bastion_keypair’
- Generate new, download to someplace safe on L
- Launch instance
- Security group is important
Building a work environment EC2 instance on Sprivate
- On Sprivate install a small Dedicated EC2 instance E
Encrypting the key to the private subnet instance
New Linux instances should have Gnupg installed, otherwise use:
sudo apt install gpg
To encrypt
$ gpg -c filename
Output:
Enter passphrase: Enter passphrase again:
To decrypt
$ gpg filename.gpg
Now you have a mechanism for encrypting access to your private subnet instance on the bastion. There are two considerations that follow:
- The private subnet instance key should be set aside in a secure location by the admin building the system so that corruption of the key does not make the instance completely inaccessible.
- The private subnet instance key on the bastion should be regularly encrypted so that a breach of the bastion does not grant the black hat access to the private instance.
1E. Server side encryption S3 bucket
- The file must be encrypted on L
- We upload this file to S3 and stipulate “encrypt this when it comes to rest in S3”
- S3 manages this
- We create an associated policy that only allows this type of upload
- Therefore a not-encrypted-at-rest request will be denied
As a guide see the S3 AWS encryption link.
- Click Server-Side Encryption
- Click on Amazon S3-Managed Encryption keys in the left sidebar to arrive at this documentation.
Copy the code box contents Go to console S3 bucket Permissions tab Bucket Policy button Paste Replace in two places: actual bucket name
PutObject command: must have server-side-encryption set to AES256 (that is the name of the encryption algorithm) AND must have server-side-encryption set to true.
“Encrypted in transit” is done via the https endpoint to S3.
We are now configuring the S3 Endpoint. In so doing we selected the VPC RT (not the public subnet RT; could use that) We are concerned about S3 traffic S3 Endpoint is a new type of Gateway that gives S3 access from Private subnet direct into S3 without any traverse of the internet.
WARNING: Kilroy: After I added the S3 Endpoint the NAT gateway entry had vanished from my VPC routing table. This is bad. Right now the procedure is going to be: After S3 EP go examine RT and re-add NAT gateway if it is not properly present. holy cow!!!!!!!!!!!!!!!
Created S3 bucket
1E. Ancillary components
This section describes the use of automated services, data bases tables, IOT endpoints and other AWS features to augment the SCE. Such ancillary components may or may not touch directly on PHI, an important differentiator as only HIPAA-aligned technologies are permitted to do so.
- Set up a DynamoDB table to track names of uploaded files
- Set up a Lambda service
- Triggered by new object in bucket in the S3 input bucket
- This Lambda service is managed using a role
- Set up an SQS Simple Queue Service Q
- Create an SNS to notify me when interesting things happen
1F. Encryption
Our EC2 instance will maintain encrypted PHI on an Elastic Block Storage (EBS) volume by requiring that this EBS volume be encrypted. That is, this volume must be created with the ‘encryption’ check-box checked. Once this is done we mount a file partition on the EBS. This procedure is described on the EC2 page.
In creating the EBS: Volume type can be General Pupose. For EBS costing and performance refer to this link. Notice the EBS volume has a Region and an Availability Zone which must match the target EC2 where it will be attached.
The Master Key issue is ignored here; we assert that the default Key is simplest and secure. Using the default Key encrypts this data at rest. So that’s done. (Working with your own set of keys would be part of risk management: Should the keys be compromised? etcetera. There is some associated hassle.) We intentionally do not encrypt the root volume. This is another risk mitigation choice.
ok done: hipaa_ebs_ec2_private
Next log in to EC2 on the private subnet:
- log in to the bastion server
- used copy-paste to edit a file on the bastion called ec2_private_keypair.pem
- I did a bad paste and was missing the —–BEGI
- on this file we ran chmod 600 on the pem file
- ssh -i
10.0.1.248 - notice this ip address is in the console Description tab when highlighting the private subnet EC2 instance
- Notice that the pem file on the bastion would immediately compromise the EC2 on the private subnet
- That sure sucks for you
Using (sudo) fdisk to create the partition on the raw block device (fast: writing the partition table) will blow away anything already there.
% aws s3 cp s3://bucket-name/keyname .
Kilroy that should probably be compared to using ‘scp’.
S3 key names versus file names
In the above copy command I knew in advance the keyname that I wanted to copy to the EBS volume. This is because it was identical to the filename that I uploaded to this S3 bucket from L. That file was pushed from L using the AWS browser console but it could also be pushed using CLI or using a utility program. The important point is that filename and keyname are the same thing.
Transferring to the instance: scp
Last encryption note: SSL is used by the CLI be default; so our EC2-private command ‘aws s3 … etc’: Look at cli/latest/reference for the link on this. This means that S3 to EC2private is encrypted in transit. The EBS /hipaa is encrypted at rest. Done.
1G. Auditing
SCE activity must be logged in such a manner as to permit subsequent tracing of PHI data access and ongoing monitoring of the security state of the system.
CloudTrail and CloudWatch
CloudTrail is logging the API calls to my account. Whether through the console, the CLI, the APIs directly: All logged in cloud trail once it is enabled. They all use the same APIs; so we log on the API calls. Logs to S3.
Here is the key thing: Enable cloud trail which creates a destination S3 bucket where all of the logging will go.
Best practice is to turn on Cloud Trail in all of your regions; so you are not blind. “Either you are logging or it is gone.”
Cloud Watch is more for monitoring: Performance metrics.
In both cases there is never PHI data in the log: PRovided ss#s are not in the filenames (for example)
And S3 has its own internal logging mechanism as well.
- Create a new bucket hipaa-s3-access-logs with vanilla settings
- Locate the existing inbound data bucket > Properties > Logging > enable > stipulate the access logs bucket; add a tag…
This will have http traffic details; where stuff was coming from for example
AWS Config
Cloud trail tells you what’s happening in terms of the API AWS Config tells you what changed
Use them together to see if something is happening / happened of concern
High level set up and then more detailed is possible
Console > MAnagement > Config
Think of Config (like Cloud Trail) as account-wide, not “per resource” so tagging with the PIT is not correct.
My process was pretty default.
So now we have Cloud Trail, S3 logging and Config operating on this account. So as we get more sophisticated we could dig in to Cloud Watch.
1H. Disaster Recovery
Indicate awareness; up to CISO to provide hurdles
1I. Operating within the environment
I begin by starting a windows laptop connected to the internet and run PuTTYGen. I use this to convert my .pem access file to the bastion server to a .ppk file. This is just a necessary formality. I then start PuTTY and use the Connection / SSH / Auth panel to Browse to my .ppk key file.
I look on the AWS Console at my EC2 instance, the bastion server for this VPC, and note the current ip address. If this is an elastic ip then it will not change over time; which is useful. I enter into the PuTTY Session main window the Host Name ec2-user@’ip-address’ (Note that ec2-user is the verbatim string; ip-address you must substitute, for example 35.27.93.105. Port is 22.
Before clicking the Open button in PuTTY I first give this session a name and Save it. This can be loaded next time to make the process faster. Now click Open and after confirming in a dialog if all went well I see a Linux command prompt. I immediately update my instance using
% sudo yum update
I have obtained a .pem keypair file for access to my private subnet EC2 instance. I use scp (actually the application WinSCP) to copy this pem file (no need to translate to .ppk) to the bastion server. It should appear in my ec2-user home directory. Now I log in to the private EC2 instance using
ssh -i ec2_private_keypair.pem ec2-user@10.0.1.248
Notice that this uses the private subnet ip address 10.0.1.248. This ip address can be seen in the AWS console by highlighting the private EC2 instance and reading the Description tab found below the instance table. Again I have a command prompt and I issue
% sudo yum update
This is obtaining updates via the NAT Gateway; so while this machine is able to obtain and use PHI it is also able to safely get updates and install other software from the web. Being a Python programmer I also issue
% sudo yum install anaconda
Now I can turn my attention to obtaining a dataset from an S3 bucket to my local block storage (disk drive). This narrative is continued below in Part 2 under ‘operating within the POC’.
Part 2. POC A, a SCE with a small synthetic dataset
2A. Documenting the creation of the environment
2B. Creating the synthetic dataset
The following is a snapshot of some Python code that generates two CSV files with imaginary health data. The data are non-trivial insofar as three of the measured values are related to vitals.
# 100 people (all named John) live in a small town with one doctor. They appeared in this town
# on October 30, 1938 all at once. Every day or two one of them at random visits the doctor
# where his vital signs are recorded: Blood pressure (two numbers), respiration rate, heart rate,
# blood oxygen saturation, body temperature (deg F) and weight (pounds). The doctor also asks
# 'Since your last visit how many albums have you purchased by Count Basie? By T-Pain? By the
# Dead Kennedys?' This process generates a 10,000 row time-series database over 41 years.
#
# The code below builds 3 tables (each being a list of lists) and these are written to CSV files.
# The following are some notes on these tables and related parameters.
#
# Tstudy is the first day of study data, morning of October 30 1938
# Tborn is the latest possible date of birth, Dec 31 1922 (so all participants are 16 or older)
# However all participants give their DOB as August 26 1920.
#
# The Python random number generator is given a fixed seed so that this code always generates the
# same patient history.
#
# 1. patient table p: Surname, Given Name, DOB, (height feet, inches), patient ID
# 2. patient parameters pp: for internal use
# 3. time series data ts: Across all patients
#
import datetime
import random as r
import csv
Tborn = datetime.datetime(1922,12,31,0,0,0)
Tstudy = datetime.datetime(1938,10,30,0,0,0)
pName = 'patients.csv'
ppName = 'patientParameters.csv'
tsName = 'timeseries.csv'
# Keep results reproducible using a fixed random number seed
r.seed(31415)
lc = ['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z']
uc = ['A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z']
def RandLastName():
return uc[r.randint(0,25)]+lc[r.randint(0,25)]+lc[r.randint(0,25)]+lc[r.randint(0,25)]
def cmtoftin(ncm):
if ncm < 50*2.54: return {5,8}
nin = ncm / 2.54
nft = int(nin/12)
nin = int(nin - 12*nft)
return (nft, nin)
def ftintocm(height):
height_in = height[0]*12 + height[1]
return int(height_in*2.54)
def someheight():
hgtLow = 157
hgtHi = 198 # from 5 foot 2 to 6 foot 6
return cmtoftin(r.randint(hgtLow, hgtHi))
sysMin = 90
sysMax = 129
diaMin = 60
diaMax = 84
rrMin = 10
rrMax = 20
hrMin = 40
hrMax = 100
osMin = 95.0
osMax = 99.0
btMin = 97.0
btMax = 99.1
mMin = 98
mMax = 280
def ModelBaseE(hr, sys, dia, bmi):
if hr > 58 and hr < 62 and sys-dia > 30 and bmi < 22: return 1
return 0
def ModelTPain(rr, os, height):
return float(rr) + 2.0*(os-95.0)+0.2*(ftintocm(height)-157)
def ModelDK(weight, bt):
if weight < 150 and bt < 97.4: return 1
return 0
def RandomSystolic(a,b):
return r.randint(a,b)
def RandomDiastolic(a,b):
return r.randint(a,b)
def RandomRespirationRate(a,b):
return r.randint(a,b)
def RandomHeartRate(a,b):
return r.randint(a,b)
def RandomOxygenSaturation(a,b):
return r.uniform(a,b)
def RandomBodyTemperature(a,b):
return r.uniform(a,b)
def RandomMass(a,b):
return r.randint(a,b)
def BMI(height,mass):
height_in = height[0]*12+height[1]
return 703.0*mass/(height_in*height_in)
nPatients = 100
bornDay = datetime.datetime(1920,8,26,8,30,12)
p=[]
pHdr = []
pp=[]
ppHdr=[]
pSurnameIndex = 0
pFirstNameIndex = 1
pDOBIndex = 2
pHeightIndex = 3
pIDIndex = 4
pHdr.append(['Surname','Given name', 'DOB', 'height', 'ID'])
p.append(['Bigboote','John',bornDay,someheight(),0])
p.append(['Yaya','John',bornDay,someheight(),1])
p.append(['Smallberries','John',bornDay,someheight(),2])
p.append(['Parker','John',bornDay,someheight(),3])
p.append(['Whorfin','John',bornDay,someheight(),4])
p.append(['Valuk','John',bornDay,someheight(),5])
p.append(['Gomez','John',bornDay,someheight(),6])
p.append(['OConnor','John',bornDay,someheight(),7])
p.append(['Emdall','John',bornDay,someheight(),8])
p.append(['Gant','John',bornDay,someheight(),9])
p.append(['Manyjars','John',bornDay,someheight(),10])
p.append(['Milton','John',bornDay,someheight(),11])
pDone = len(p)
for i in range(nPatients-pDone):
while True:
nextName = RandLastName()
if not nextName in p:
p.append([nextName,'John',bornDay,someheight(),i+pDone])
break
with open(pName,'wb') as patientFile:
csvWriter = csv.writer(patientFile, dialect='excel')
csvWriter.writerows(pHdr)
csvWriter.writerows(p)
# The next table is pp for 'patient parameters' and it requires some explanation
# It will be used for two purposes: To keep static range parameters for the patient's vital
# signs (used to generate the time series data on a per-patient basis) and it will also
# be used to track cumulative values for the three 'effect' categories BaseE, TPain and DK.
#
# In passing: These are meaningless categories. Their similarity in sound to musical acts
# is coincidental.
#
ppIDidx=0
ppS0idx=1
ppS1idx=2
ppD0idx=3
ppD1idx=4
ppRR0idx=5
ppRR1idx=6
ppHR0idx=7
ppHR1idx=8
ppOS0idx=9
ppOS1idx=10
ppBT0idx=11
ppBT1idx=12
ppM0idx=13
ppM1idx=14
ppSUMBidx=15
ppSUMTidx=16
ppSUMDKidx=17
ppHdr.append(['ID','S0','S1','D0','D1','RR0','RR1','HR0','HR1','OS0','OS1',\
'BT0','BT1','M0','M1','SUMB','SUMT','SUMDK'])
for i in range(nPatients):
s0 = r.randint(sysMin, sysMax)
s1 = s0 + r.randint(4,20) # a range of systolic pressures (mmHg)
d0 = r.randint(diaMin, diaMax)
d1 = d0 + r.randint(4,10) # a range of diastolic pressures
rr0 = r.randint(rrMin, rrMax)
rr1 = rr0 + r.randint(2,8)
hr0 = r.randint(hrMin, hrMax)
hr1 = hr0 + r.randint(10,20)
os0 = r.uniform(osMin, osMax)
os1 = os0 + r.uniform(1.0,2.0)
bt0 = r.randint(sysMin, sysMax)
bt1 = bt0 + r.randint(3,20)
m0 = r.randint(mMin, mMax)
m1 = m0 + r.randint(3,40)
pp.append([i,s0, s1, d0, d1, rr0, rr1, hr0, hr1, os0, os1, \
bt0, bt1, m0, m1, 0, 0, 0])
# Study begins on October 30 1938, generates 10,000 records and continues for about 41 years
ts = []
tsHdr = []
tsHdr.append(['date','ID','systol','diastol','resp.rate','heart rate','OSat','temp',\
'weight','BMI','BaseE','TPain','DK','sum BaseE','sum TPain','sum DK'])
Time = Tstudy
for i in range(10000):
# generate this timestamp
thisID = r.randint(0,99)
# for each of the following vitals we allow a bit of correcting goofy values
# blood pressure
thisSys = RandomSystolic(pp[thisID][ppS0idx], pp[thisID][ppS1idx])
thisDia = RandomDiastolic(pp[thisID][ppD0idx], pp[thisID][ppD1idx])
if thisDia >= thisSys - 3: thisDia = thisSys - 4
# Respiration and Heart rates
thisRR = RandomRespirationRate(pp[thisID][ppRR0idx], pp[thisID][ppRR1idx])
thisHR = RandomHeartRate(pp[thisID][ppHR0idx], pp[thisID][ppHR1idx])
# blood oxygen saturation
thisOS = RandomOxygenSaturation(pp[thisID][ppOS0idx], pp[thisID][ppOS1idx])
if thisOS > 99.4: thisOS = 99.4
# body temperature
thisBT = RandomBodyTemperature(pp[thisID][ppBT0idx], pp[thisID][ppBT1idx])
# body weight and BMI
thisMass = RandomMass(pp[thisID][ppM0idx], pp[thisID][ppM1idx])
thisBMI = BMI(p[thisID][pHeightIndex], thisMass)
# three 'diagnostic observations'
thisBaseE = ModelBaseE(thisHR, thisSys, thisDia, thisBMI)
thisTPain = ModelTPain(thisRR, thisOS, p[thisID][pHeightIndex])
thisDK = ModelDK(thisBMI, thisBT)
# track the cumulatives of the diagnostics
pp[thisID][ppSUMBidx]+=thisBaseE
pp[thisID][ppSUMTidx]+=thisTPain
pp[thisID][ppSUMDKidx]+=thisDK
thisSumBaseE = pp[thisID][ppSUMBidx]
thisSumTPain = pp[thisID][ppSUMTidx]
thisSumDK = pp[thisID][ppSUMDKidx]
# create a new record in the time series
ts.append([Time, thisID, thisSys, thisDia, thisRR, thisHR, thisOS, \
thisBT, thisMass, thisBMI, thisBaseE, thisTPain, thisDK, \
thisSumBaseE, thisSumTPain, thisSumDK])
# add a random number of days to the time
Time += datetime.timedelta(days=r.randint(1,2))
with open(tsName,'wb') as timeseriesFile:
csvWriter = csv.writer(timeseriesFile, dialect='excel')
csvWriter.writerows(tsHdr)
csvWriter.writerows(ts)
# Write the patient parameters pp[] at the end to record cumulatives on BaseE, TPain, DK
with open(ppName,'wb') as patientParameterFile:
csvWriter = csv.writer(patientParameterFile, dialect='excel')
csvWriter.writerows(ppHdr)
csvWriter.writerows(pp)
2C. Installing software and operating POC A
2D. Concluding remarks on POC A
Part 3 POC B including OMOP unrestricted dataset ported to AWS Redshift
3A: New SCE
Follow the instructions using a new PIT. I will use omop.
3B: OMOP to Redshift
This POC is a good direction for a number of reasons; including the fact that UW Med has an initiative underway to create an OMOP warehouse from clinical data.
From the website is a Quick Link to an Unrestricted Vocabulary. From the README here are the steps to load the vocabulary data.
- Download vocabulary files to local drive and unzip them or (Redshift)
- Upload gzipped files to S3 storage
- Create target tables
- Transfer data from files to tables
- Redshift
- copy vocabulary.vocabulary from 's3://.../vocabulary.txt.gz' credentials 'aws_access_key_id=;aws_secret_access_key=' delimiter '\362' ACCEPTINVCHARS GZIP emptyasnull dateformat 'auto';
3C: Visualization
OHDSI has several open source tools that have data visualization, specifically Atlas. Challenge then becomes: Configure a website for us to view the Atlas output operating on the synpuf dataset (OMOP; must agree this is apples/apples). This gets us to a dataset in omop, a data viz tool, hosted on the cloud with a web GUI.
(Looking ahead: What other data viz and analytic tools does the cloud environment give us access to and can we prototype some use case there? From there a notionally short jump to get live data and a ‘real’ demo (not synthetic.))
Installing ATLAS
See this page.
The challenge is going to be installing the DB and then the web server components on the right parts of the VPC.
Step 1 is Install the OHDSI WebAPI and configure the appropriate sources.
… and so on …
Appendix: Fossil residual please refactor back into the above
Procedure Log
Create a VPC V
- Use the name ‘hipaa’; should be unique.
- CIDR as shown is typical.
- Dedicated Instance means: Nobody else allowed here.
- I added a tag indicating that I originated the VPC.
Create a subnet
Public subnet addresses will be of the form: 10.0.0.2, .3, .4, … .254
Take note of the AZ:
We could do multiple public sub-nets by creating more than one in multiple Azs; that is a big-time concept.
Now the private one:
Attach it to the VPC:
Now for the NAT Gateway
Choose the public one in czarhipaa
Notice we Created a New EIP
Now the Route Table
Here they are (including the default main one):
Edit and modify as shown:
Save
And then under Subnet Associations tab: Edit:
Now let us go back to the Route Table selector
Subnet Associations tab:
Now for the Endpoint
Notice that this has Full Access; we will restrict access at a later step.
end as of Jan 27 2017.
Risk
This section identifies points of risk and their severity. Severity is described both ‘when protocol is properly observed’ and ‘when protocol is not observed’. That is: We provide examples of how failure to follow protocols could result in the compromise of PHI. There is in all of this a notion of diminishing returns: A tremendous amount of additional effort might be incorporated in building an SCE that provides only small reduction of risk.
VPC creation: Manual versus Wizard
Dedicated instances
We drive cost up using dedicated instances on Sprivate. It is technically feasible to not do this but there is an attendant cost in time and risk.
Extended key management strategy
Encryption keys here are taken to be default keys associated with the AWS account. It is possible on setting up the SCE to create an entire structure around management of newly-generated keys. This is a diminishing-returns risk mitigation procedure: It may create a profusion of complexity that is itself a risk.
One open question is whether a single AWS account should / could / will be used to provision multiple independent research projects, each with one or more respective data systems.
- Log in to B and move K to E
- Observe that material encrypted
- Maybe instead we should be tunneling directly to E from L
-
Use an AMI to create a processing EC2 W
- Also with ENC
- Create S3 buckets
- S3D for data
- S3O for output
- S3L for logging
-
S3A for ancillary purposes (non-PHI is the intention)
- Such S3 buckets only accept http PUT; not GET or LIST
- Create an S3 bucke S3O for output
- Create an S3 bucke S3L for logging
- Create an S3 Endpoint S3EP_D in V
- Create an S3 Endpoint S3EP_O in V
- Create an S3 Endpoint S3EP_L in V
- “S3 buckets have a VPC Endpoint included… ensure this terminates inside the VPC”
- Create role R allowing W to read data at S3EP from S3