Introduction
The purpose of this page is to walk through GitHub procedures with two implementations in mind:
- A Jekyll implementation (e.g. http://cloudmaven.org) that renders markdown (.md) properly.
- A Jupyter Notebook: Both static rendering and as a backup of a dynamic instance.
Using a code repository (distinguish: not a data repository) like GitHub accomplishes:
- You have a safe back-up of your code base
- You can work on your code with others simultaneously, managing versions
- You can take advantage of interpreters like Jekyll that build documentation pages
- You can maintain versions of your code for development, testing and deployment (use)
Links
Warnings
- For a Jekyll instance such as this website: Work from the gh-pages branch, not the master.
- You risk ‘breaking’ your GitHub implementation if you work on the wrong branch.
- If GitHub is balking (throwing fail/error messages): Use ‘git status’ on the command line and diagnose the output.
- For example a ‘rebase’ in progress (unresolved) can be halted using ‘git rebase abort’ but be sure you know what you are doing.
- Once ‘git status’ is ok you can return to business as usual.
- GitHub can sometimes be mysterious. When in doubt: Make an independent local copy of the repo folder first.
- While Jekyll renders markdown there does not appear to be a reliably good way of rendering LaTeX.
- In research this is important. Until there is a fix we are obliged to render to pngs and embed them as images.
GitHub Basics
GitHub API
GitHub raw file recovery
GitHub Commit from Command Line on Windows
This assumes you already have a GitHub repo and a local copy. You have modified something in the local copy and you have permission to just execute a push that will override anything on the GitHub repo.
- Start the Power Shell on a Windows machine connected to the internet.
- Navigate to the base directory of the repository.
- Issue these in sequence; note I have paraphrased what they do
- git status state the current status of the local repository
- Is there a ‘rebase’ in the response? You may need to issue ‘git rebase abort’ but be sure this is safe to do
- git pull update my copy of the repo from GitHub to latest
- git add . stage everything new recursively (this folder on down) for a commit
- git commit -m “a comment” creates a ‘commit’ of the current state of the local repo
- git push origin master update the GitHub repo based on mine
- This push may require login information: login name and password
- git status state the current status of the local repository
Jekyll on GitHub
Jekyll is a GitHub repo that includes rendering software ‘for itself’. That is: If you make a copy of the Jekyll repo and rename it something else, like ‘Hyde’, it will be visible on GitHub as both a normal repo (let’s call that the back door) and as a rendered website (the front door). The way this works is your version will start out with some default files that have the markdown file extension ‘.md’. These you can modify to suit your own purposes. When you hit the front door Jekyll manually creates from these markdown files some pretty html content which renders in your browser. Follow the recipe provided by the Jekyll documentation and you can start building out content in Hyde. This is what we have done with http://cloudmaven.org.
Notice that there is a side comment (Kilroy) needed here about the distinction between the front door URL and the DNS entry.
Jupyter GitHub repo on AWS EC2
Suppose your EC2-based Jupyter Notebook is publicly visible. It might be password-protected (it is by default) but passwords have a way of getting handed around and this is not a highly secure situation. Someone logs on to your Notebook and deletes a page or makes some not-too-useful changes. You want to revert to the old version: This sounds like a job for GitHub.
Install the git utility on the EC2 instance: First ssh via PuTTY (as I am using a Windows machine).
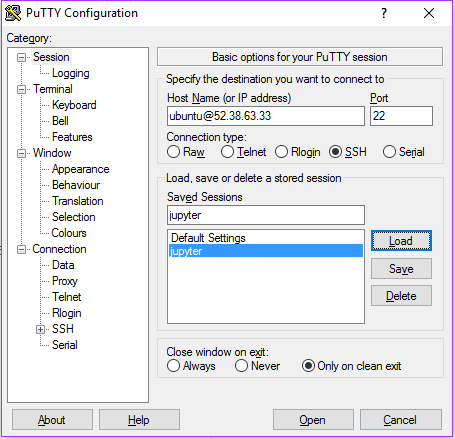
Take care of updating the Operating System first
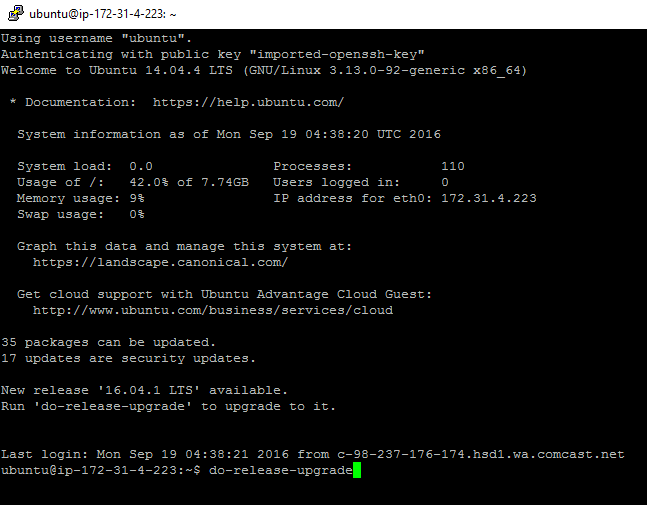
Interestingly this takes twenty minutes or so; and I have to babysit it; plus a reboot. It is an administrative task even though I am on the cloud.
Now I can run
% sudo apt-get install git
however I find that ‘git’ is already installed; so that is actually not necessary in this case.
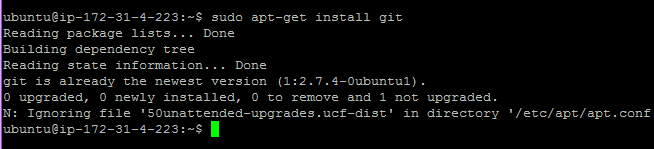
I want to make a repo from the Notebooks folder so
% cd Notebooks
% git init
% git add .
% git commit -m "starting othermathclub git repo"
In browser go to http://github.com/myname and Create a new Repo (with a README).
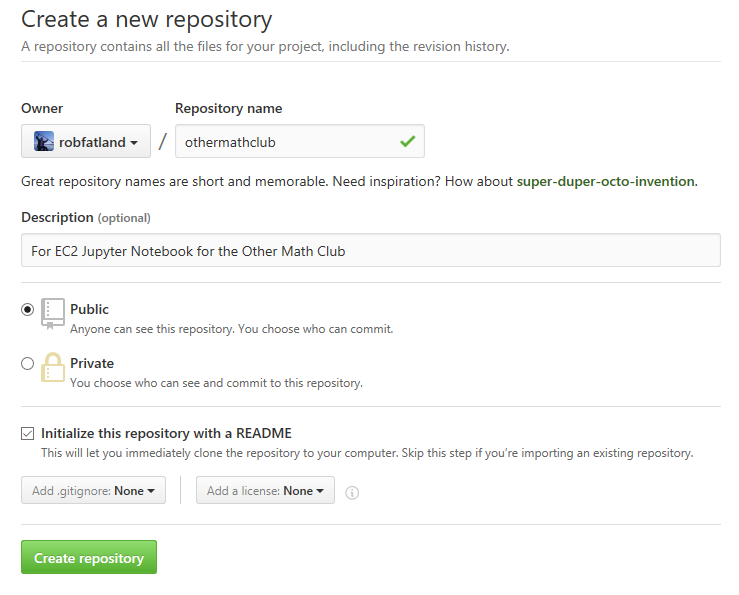
Grab the repo address to the clipboard; call that ‘link’; back on the EC2 instance:
% git remote add origin 'link'
% git push origin master
(fails because the README file at the GitHub repo doesn’t exist here)
% git stash
% git pull 'link' master
This goes to some little text editor… ctrl-x to get out of it.
% git push origin master
Fails because the data folder contains a file larger than 100MB; so the lesson here is don’t put large files in a repo unless you pay for the extra storage account.
I relocate the data folder outside the repo folder.
% mv data ..
This proves to be a mistake, it would seem. Subsequent efforts to commit/push do not go well. I could also have added the offending large file to .gitignore but I chose this method instead, just by-the-by.
Finally we come up with a convoluted solution:
% git filter-branch -f --index-filter "git rm -rf --cached --ignore-unmatch data" -- --all
This seems to convince (see screencap) git that the two large datafiles really are not part of the repo.
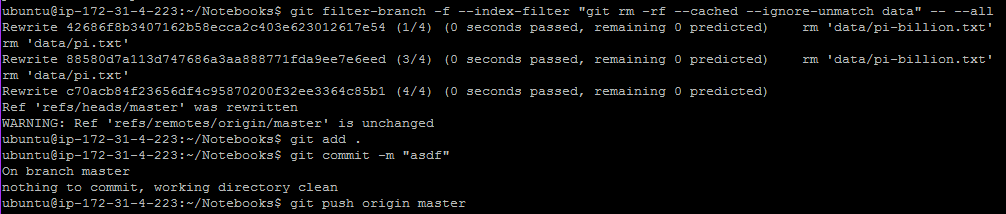
We then proceed with add . (which adds the entire current directory to some entity) and commit (which I sorta get) and push origin master.
Git short-course notes
Notes from a class offered at the WRF Data Science Studio by the eScience Institute, January 13 2017. (Bernease Herman is the instructor.)
> git add FILEPATH -> stages new material; up until this is done the stuff in FILEPATH is "untracked"
> git commit -m "message" -> commits those changes to the repo
This is local and (after iteration) produces a stack of changes. Git push and git pull will interact with a remote repo.
WARNING: Using stash is only advised for one stash.
> git stash will only stash tracked files
> git stash -u will also stash un-tracked files (they exist but have not been added)
> git stash apply will re-instate the stash into its former state
Branches
Let’s try a great idea to see if it works out; if so we will bring it back in; the usual diverge / merge diagram.
> git branch feature1
> git branch
feature1
* master
> git branch -d feature1 deletes the branch
Let’s ignore that delete and assume feature1 branch exists.
> git checkout feature1 'checkout' is the branch choice command
> git checkout master
So the actual chain of events would be (in git command sequence)
> git branch f1
> git checkout f1
> git branch verify we are working on the f1 branch
> vi file.txt edit and save file we want to change
> git add file.txt stage that file
> git commit -m "msg" commit that change (again this is to branch f1)
> git checkout master
> git merge f1 merges f1 (including the new commit) with master
> git branch just to note that both branches still exist
> git branch -d f1 deletes the f1 branch; now only master exists
Notice that with the ability to create branches we can work on multiple versions of the same code base in parallel.
WARNING The reason stash exists is to hang on to stuff without a commit. Otherwise: Commit is necessary.
Now the GitHub website might have a public repo that I would like to work on. Fork to my own GitHub account and copy the URL
> cd GitHub that is: Go to the parent directory of where we want stuff
> git clone <URL-from-above>
Triangle concept
Suppose we have a project leader Valentina and we want to work with her. She maintains her copy of the code; and there is our GitHub repo as well. We thirdly have our local repo creating a triangle. The process will be to generate changes and then request that Valentina integrates them into her repo which is the main one. We work locally, integrate with our online GitHub.com repo, and then issue pull requests to Valentina from there.
- We want a triangle of 3 repos: Local, my GitHub, and Valentinas.
- We give the latter two informal names (although ‘origin’ is a default): origin and upstream.
upstream will be Valentina’s. origin will be our online repo at GitHub.
- We make local changes.
- We can pull from Valentina to stay up to date.
- We can push to ‘origin’ (our GitHub.com repo)
- We can make requests to Valentina (pull request) to grab our changes from our ‘origin’ repo.
- We make these pull requests from the browser / GitHub repo; not from our command line.
‘git pull origin master’ means I update my local copy from my GitHub repo (not the source repo)